
Schemanator: Love Child of Deployinator and Schema Changes

We've previously written about our sharded master-master pair database architecture and how that and the Etsy ORM allows us to perform schema changes while keeping the site up. That we can do this at all is really awesome but to actually do this is still hard, risky and time-consuming. We run the site on half of our database servers while we make schema changes to the other half. Then we switch sides and do it again. It's many steps on many machines and it's happening while 100+ developers are pushing code. Let's take a closer look at how we pull this off and the automation we've developed around this process.
I want to pause to acknowledge that being able to run the site on half of our database servers is in itself the result not only of good design in the ORM but of good ongoing capacity planning in making sure we can carry a full load on half the servers.
To understand Schemanator let's first take a look at how we did schema changes "by hand". To complete a schema change we need to change the ORM's configuration a total of 4 times - first to take one half of the databases out of production so we can apply change to them and then to put them back. Then we take the other half out and apply changes and finally put them back. At Etsy we can deploy relatively quickly - generally less than 20 minutes from commit to live -- and we have an even more streamlined process for updating just the application configuration -- a "config push" as we call it. The challenge with this comes from the fact that at any point during a day, people are waiting their turn to deploy code in our push queue. To do our schema change, we'll need to wait through the push queue 4 times. Not hard, but not amenable to getting things done quickly.
Once we've done the first config push to pull out half the DBs, we're ready to apply the schema changes to the set of dormant servers. For this we'd use some shell-fu in a screen or tmux session to run commands on all the databases at once. When those changes were done, we'd get back in the push queue to put the updated DBs back in production, watch that it's stable and then take the other side out. Then go back to the terminal, connect to all the other databases and run the changes on them. When that's done, it's back to the push queue to return the ORM to its full configuration. Along the way we'd have to deal with Nagios, run checksums on the new schemas on each host, and monitor DB status and site errors. And at the end we should end up with something we can call a log of the changes we made.
We did versions of that process for a while. It worked but no one is perfect and we did have an outage stemming from errors made while doing schema changes. This incident helped crystalize the "quantum of deployment concept as applied to schema changes" for us. We asked ourselves "What's the smallest number of steps, with the smallest number of people and the smallest amount of ceremony required to get new schemas running on our servers?" With an answer to that, we knew we could, and had to, put a button on it.
Thus was born Schemanator.
From Continuous Deployment to Concurrent Deployment
From the description of the schema change process above it&39;s clear that one of the pain points is having to wait in the push queue to deploy configuration changes. In order to be truly awesome, Schemanator would have to provide an avenue for the operator to bypass the push queue altogether. In practical terms, not having to wait in the queue shaves at least an hour off the whole process. This part of Schemanator is the first part we wanted to address since it delivered the most overall time savings in the shortest time.
To help understand how we made this part work here&39;s a bit more about our ORM setup. On each request, the configuration file is read in. Part of that configuration is the set of DSNs for all available database servers. We store these in a hash keyed by the shard number and side like this:
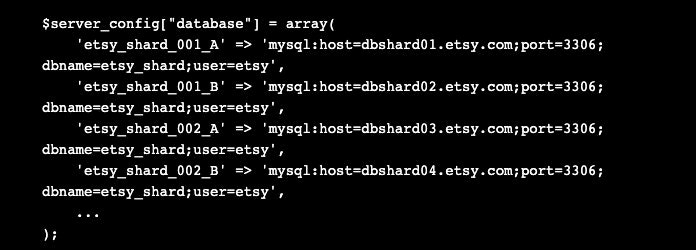
Before Schemanator, we would literally just comment out the lines with the DSNs we didn't want the ORM to use. We didn't want to automate commenting out lines of code in our config file, and even if we did, doing so would have still left us having to wait in the push queue. So we made a slight change to the ORM setup routine. When the ORM sets up, it now also checks if a special file -- a "disabled connections" file exists. If it does, it's read in as a list of DSNs to ignore. Those servers are skipped when the ORM sets up and the application ends up not using them. Since the config is read at the begining of the web request and PHP is shared nothing, once the disabled connections file is in place, all subsequent requests on that server will respect it.
By carefully deploying just that one special disabled connections file into the live docroot we get the changes we need to the ORM...and we can do this while people are pushing code changes to the site. Specifically, we updated our general deploy to exclude the disabled connections file to eliminate possible race conditions on deploy and we set up Deployinator to allow us to deploy the disabled connections file on its own.
But there was a problem. Like many php sites we use APC for opcode caching. Part of each deploy included gracefully restarting Apache to clear the opcode cache. Dropping the one file in is all well and good but we'd still have to clear it from APC. After considering some options, we chose to turn on apc.stat. This tells APC to stat each file before returning the cached opcodes. If the file is newer than the cached opcodes then re-read the file and update the cache. We run our docroot from a RAM disk so the extra stats aren't a problem. With apc.stat on we could drop in our disabled connections file and the next request will start using it. No restarts required. We did need to increase the size of our APC cache to allow this. We were able to stop doing restarts on each deploy and since most deploys only change a small subset of our codebase, we saw an improvement in our cache-hit ratio. With this process in hand, and after much testing, we were able to allow the disabled connections file to be deployed concurrently with our regular deploys.
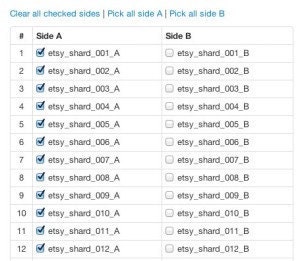
We call this part of Schemanator "Side Splitter". It provides a Web GUI for selecting which DB servers to disable and a button to deploy that configuration. Pushing the button writes and deploys the disabled connections file. There are also a number of sanity checks to make sure we don't do things like pull out both sides of the same shard. We use this not just as part of schema changes, but also when we need to pull DBs out for maintenance.
Ch-ch-changes
Next we needed a process for applying the schema changes to the databases. A number of the choices we had to make here were strongly influenced by our environment. Etsy is in PHP and we use Gearman for asynchronous jobs so using anything but PHP/Gearman for Schemanator would have meant re-inventing many wheels.
There are many things that could possibly go wrong while running schema changes. We tried to anticipate as many of these as we could: the operator&39;s internet connection could die mid-process, the application could keep connecting to disabled databases, gearman workers could die mid-job, the DDL statements might fail on a subset of servers, etc., etc. We knew that we couldn&39;t anticipate everything and that we certainly couldn't write code to recover from any possible error. With that awareness - that something unexpected would eventually happen during schema changes - we designed Schemanator to allow the operator to pause or stop the process along the way. Each sub-task pauses and shows the operator an appropriate set of graphs and monitors to allow them to evaluate if it's safe to proceed. This increases our liklihood of detecting trouble and gives us a way to bail out of the process, if that is the best course of action.
Central to Schemanator is the concept of the "changeset" - a data structure where we store everything about the schema change: the SQL, who created it, test results, checksums, and more. The changeset acts as both a recipe for Schemanator to apply the changes and a record of the work done.
The early parts of the Schemanator workflow center around defining and testing the changeset. To test a changeset, a gearman job loads up the current schema with no data and applies the changes there. If there are errors the changeset will be marked as failing and the errors reported back. We also generate the checksums we'll look for later when we apply the changes in production.
We recently added a test that inspects the post-change schema to make sure that we're keeping to our SQL standards. For example, we make sure all tables are InnoDB with UTF-8 as the default character set, that we we don't add any AUTO INCREMENT fields, which would be trouble in our Master-Master setup. We recently had an issue where some tables had a foreign key field as INT(11) but the related table had the field as BIGINT. This caused errors when trying to store the BIGINT in the INT(11) field. To catch this going forward, Schemanator now checks that our keys are all BIGINTs. Once the changeset passes all the tests, it can be run.
When Schemanator runs a changeset, the first thing it does is to tell Nagios not alert for the servers we're about to update. We use xb95's nagios-api which allows Schemanator to set and cancel downtime. Schemanator's "Preflight Check" screen shows the current status of the DB cluster and also checks Nagios to see if any of the DB servers have alerts or warnings. This gives an at-a-glance view to know if it's OK to proceed.
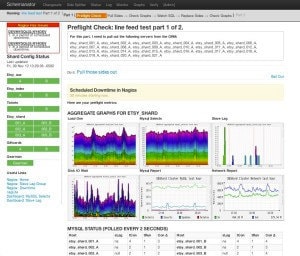
Once things look OK, the operator can click the button to "Do it: Pull those sides out". Schemanator will deploy the first of the 4 disabled connections configs. When that config is live, Schemanator drops you back on a page full of graphs where you can confirm that traffic has moved off of the pulled servers and is being adequately handled by the remaining servers. Once that is stable the operator clicks a button to apply the SQL to dormant servers. This is handled by a set of Gearman jobs - one job per database - that connect to the DBs and apply the updates. Schemanator monitors each job and polls the MySQL Process List on the DBs so the operator has good view of what's happening on each server. Any errors or checksum mismatches bubble up in the UI so the operator can decide how to deal with them.
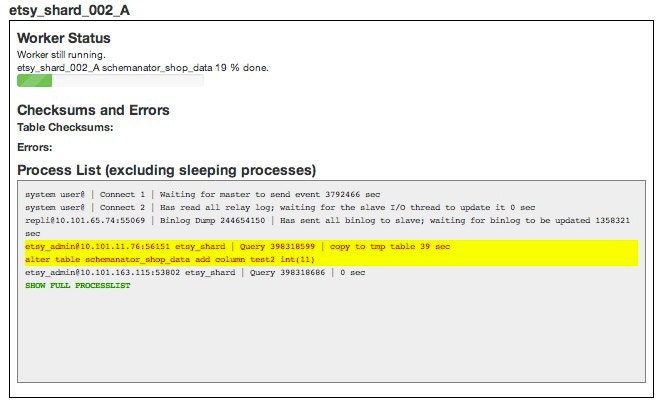
When all the workers are done, Schemanator prompts the user that it's ready to move on. From here it's a matter of repeating these steps with the right variations until the changes have been applied to all the databases. Schemanator handles setting and canceling Nagios downtime, checksumming any tables that were updated and logging everything.
We've been using Schemanator to help with schema changes for a few months now and it's achieved most of the goals we'd hope for: increased the speed and confidence we can do schema change, increased reliability that we don't forget any of the many steps involved, and freed up people from having to devote often a full day to schema changes. We generally make schema changes only once a week, but with Schemanator, if we have to do them spur of the moment, that's no longer out of the question. While Schemanator doesn't do everything, we feel it's the appropriate level of automation for a sensitive operation like schema changes.


